Method
We manufacture multi-view supervision from a single video.
Two independent crop trajectories from one monocular clip form a source and a target view. A forward-warped anchor exposes the disocclusions a new camera path would create, and a minimally adapted diffusion transformer routes textures across space and time to reconstruct the target.
Our training data pipeline. From a single monocular video we sample two independent smooth random-walk crop trajectories: one becomes the source view, the other becomes the target view of the same dynamic scene. Because the trajectories disagree spatially, the source frame at any given time cannot be copied directly to produce the target. The model must instead route textures from other source frames where the missing regions were visible, learning to reconstruct one view of a dynamic scene from a different one.
The same pipeline on real footage. Each row shows the source frames, the target frames, and the synthesized anchor for one training triplet. The black regions in the anchor are the disocclusions a new camera path would expose; the model is trained to fill them by routing textures from later source frames where the geometry was still visible. This is the supervisory signal that forces 4D structure to emerge from purely 2D data.
Implicit 4D Learning
Because the source and target crops are spatially misaligned and share occlusions, the model must search across both space and time in the source video to fill in missing target details. 4D structure emerges as a consequence, with no 3D supervision.
Self-Supervised Training
The pipeline relies only on a robust 2D dense tracker (AllTracker). It is domain-agnostic and scales to any monocular video: photorealistic footage, animation, and generative art, without restrictive domain assumptions.
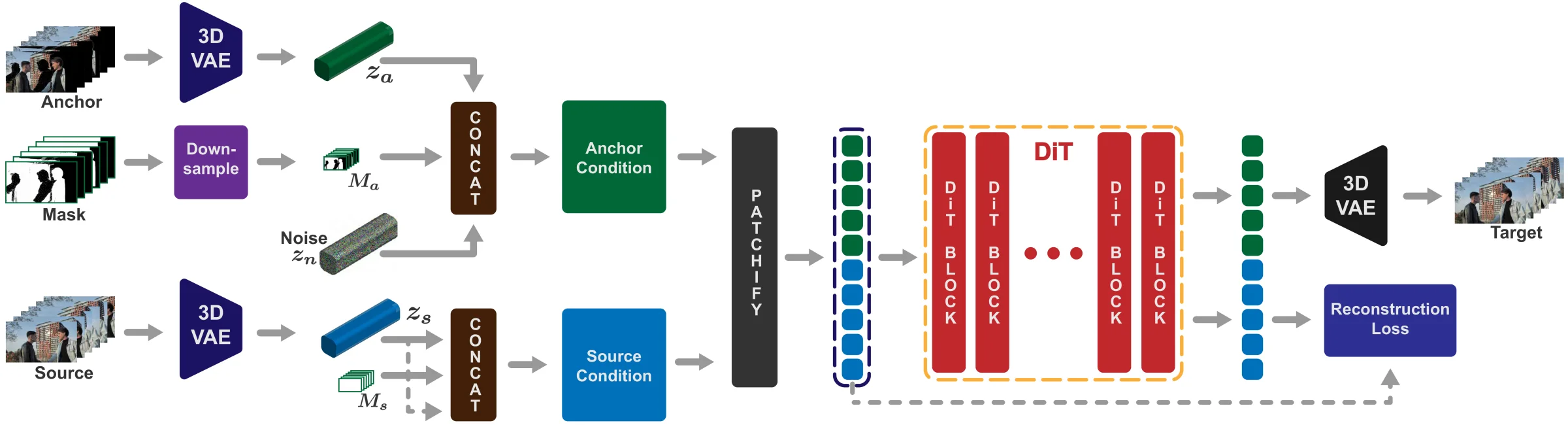
Our conditioning architecture. (1) VAE Encoding: the anchor video (Va) and source video (Vs) are independently encoded into latents (za, zs). (2) Conditioning Setup: the anchor latent pairs with a noise latent zn and downsampled mask Ma; the source latent duplicates itself in place of noise and uses an all-ones mask Ms, so any source content is usable. (3) DiT Processing: both conditioned streams are patchified, temporally concatenated, and routed through the pre-trained DiT via self-attention — letting the model do fine-grained content routing without architecture changes. (4) Source Token Management: an auxiliary reconstruction loss on the output source tokens preserves high-fidelity texture through refinement.


